
In probability theory, the urn model is one of the oldest and most generative thought experiments.
You have a bag containing marbles of different colors. You draw one, note the color, return it. Do this enough times and the draws converge toward the true distribution of marbles inside, a distribution you can’t see directly but can infer from sufficient sampling.
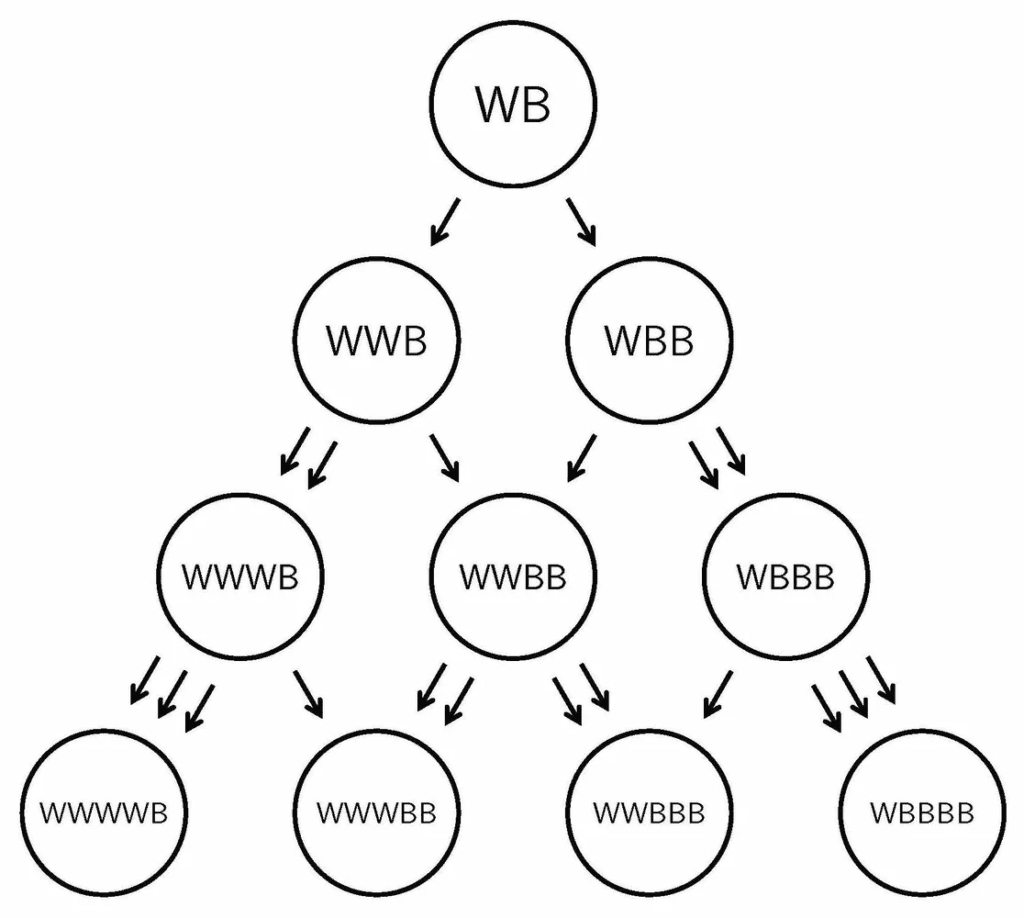
The Polya urn adds a twist.
After each draw, you return the marble plus one additional marble of the same color. Early draws compound. A color that appears early in the sequence becomes disproportionately likely to appear later. The distribution is path-dependent and self-reinforcing. Small initial advantages become structural ones.
To me, this is a useful model to apply to marketing.
Instead of trying to map out discrete and linear touchpoints along an imaginary funnel, or trying to model keyword rankings, click-through-rate curve, and conversion rate per page (a model that is quickly becoming anachronistic), you invest in actions that create cumulative advantage, a Matthew effect. You seek to increase your probability of being drawn at any given touchpoint.
The Deterministic Illusion
For twenty years, SEO operated under what was effectively a deterministic model.
A keyword had a search volume. You occupied a position. That position was observable, roughly stable, and responsive to known inputs. The relationship between action and outcome was noisy but legible, close enough to deterministic that we could build dashboards, attribution models, and quarterly forecasts around it.
(Suspend all justifiable nuances with the accuracy of search volume, stability and importance of keyword rankings, and utility of those attribution models for just a second. I’m well aware of the imperfections of the previous model).
This was always an approximation. A keyword is a sort of proxy for intent, and in reality, a page will show up for a cluster of semantically related queries aggregating toward a topic, and Google’s ranking algorithm incorporated hundreds of signals with stochastic elements. But the approximation was useful, and you really could model it out quite simply over a reasonable time period.
George Box’s dictum applied: the model was wrong but useful.
AI search forces all of those inadequacies to the surface, and marketers now need to grapple with a world in which the previous models barely hold a simulacrum of utility. It invalidates the foundational assumption that there exists a stable, observable position to optimize toward. LLMs are probabilistic at every layer: the prompt interpretation, the retrieval process, the generation of the response, and the selection of citations. The output is sampled from a distribution, not retrieved from an index. The underlying process is becoming increasingly opaque.
There’s a lot of evidence stacking up here. SISTRIX tracked 82,000 prompts across three platforms over 17 weeks. Google AI Mode rotates citation sources at 56% per week. ChatGPT rotates at 74%. Over six months, 70–90% of cited domains turn over completely. AirOps found that only 1 in 5 brands maintain citation visibility across five consecutive runs of the same query.
I’ve replicated roughly the same results with several Omniscient clients and prospects.
Query Fanout and the Evolution of the Keyword
The unit of analysis in traditional SEO was the keyword.
In AI search, the unit of analysis doesn’t exist in a stable form. When a user enters a prompt, the model generates several (the number changes by model and over time) internal sub-queries (what’s called query fanout) to retrieve information before synthesizing an answer. Surfer found only 27% of these sub-queries remain consistent across multiple runs. Sixty-six percent appear exactly once and never again.
Think about what this means.
The retrieval layer underneath AI search is itself stochastic. The model doesn’t just produce variable outputs from fixed inputs. It generates variable inputs to its own retrieval system. You’re dealing with compounded variance: uncertainty in what the user asks, uncertainty in how the model interprets it, uncertainty in what sub-queries the model generates, uncertainty in which sources those sub-queries surface, and uncertainty in how the model synthesizes and cites the results.
What all of this means is it’s very difficult to measure things and it’s also difficult to ground decisions in stable data.
An academic paper from April 2026 (Schulte et al.) formalized the measurement problem: AI search visibility should be characterized as a distribution, not a single-point outcome.
From Optimization to Probability Engineering
I often use the analogy of a cocktail party to explain Surround Sound SEO and, now, AI search.
Here’s the gist of it: imagine you’re at a cocktail party and you ask a group of people what book they are reading.
If one person mentioned The Power Broker, you may check it out. If everyone mentions it, you’ll almost certainly check it out. And if no one mentions it, well, you never had the chance to know it existed.
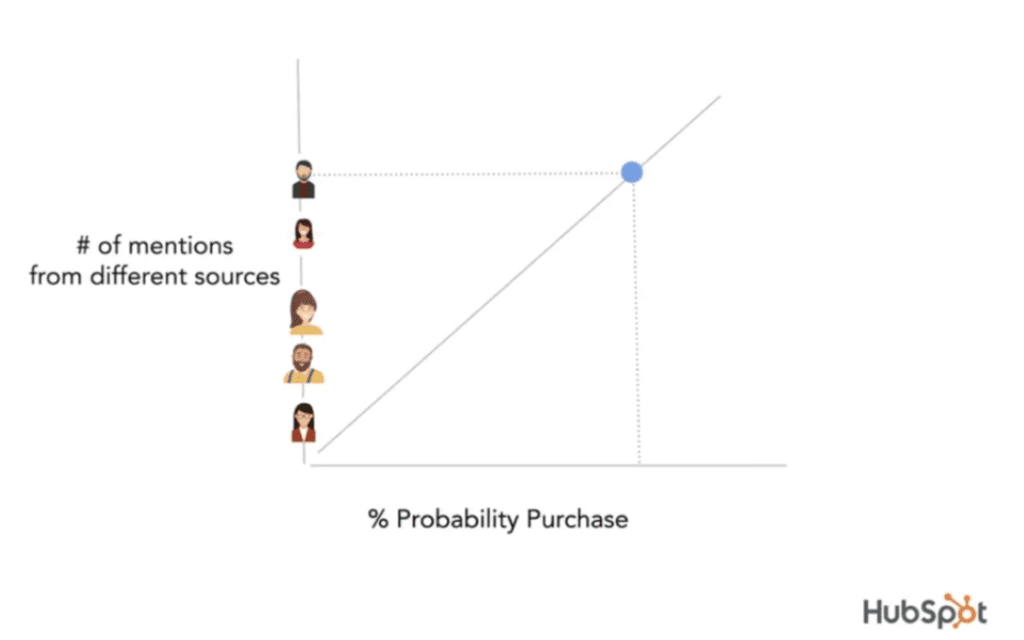
Now let’s extend the analogy. Most AI search conversation centers around a single cocktail party with a stable group of attendees.
But imagine there are endless cocktail parties happening across the world, and most of them include different attendees (with a few promiscuous party goers attending multiple).
What you want to do is increase the probability that, at any given cocktail party, the majority of people will mention your book, agency, software or running shoes when someone asks about the best book, agency, software, or running shoes.
To do that, it’s not enough to focus on begging or paying the people at any given cocktail party to mention your thing (because they might not be at the next cocktail party). To do that, brands should focus on what we call brand gravity or omnipresence.
This is not scattershot. It’s still targeted at the surface areas that are influential (to humans and agents).
But it’s focused less on spamming an individual Reddit thread, for example, and more on building a community management and advocacy program that ensures your Reddit presence is active and positive.
Reinforcement and Cumulative Advantage
The double edged sword with “probability engineering”* and AI search is that early salience tends to lead to greater salience over time.
(*I’m calling it “probability engineering” here as a slightly tongue in cheek play at the idea that everything has to be “engineering” nowadays – GTM engineering, relevance engineering, content engineering, marketing engineering. The top of Maslow’s hierarchy of coined phrases, of course, must be Engineering Engineering.)
The Polya urn model explains why.
In a self-reinforcing system, early entrants into the citation network build compounding advantages.
Brands that appear in frequently-cited sources get trained into models, get retrieved more often, get cited more, and become harder to displace. Content creators using Claude to produce blog posts run agentic research, which pulls from these sources, and produce more brand mentions. The distribution follows a path-dependent process. This is why the window to invest is now, before the urn’s distribution solidifies.
Rand Fishkin has called for a shift from attribution to influence:
“Because attribution fundamentally don’t work anymore. When you make marketing investments based, instead, on knowing who your audience is and where/how you can influence them, you can massively improve your results.”
I think this is the right approach. Of course, we’ll need to rethink our incentive structures and KPIs, because it’s not as simple as clicks and rankings. But was that ever the best approximation of value, anyway?
What Probability Engineering Actually Requires
If the job is to increase the probability of inclusion across a volatile distribution, the work is mostly upstream of what we’d consider traditional SEO or even current AEO tactics.
It is both offensive and defensive. It is making sure your positioning is echoed coherently across the web, not just on your site, but in every source an LLM might ingest. It is your inclusion on the right review sites, with reviews that substantiate your claims. It is community participation and social presence. It is podcast appearances and editorial coverage. It is building a dense, expansive web of proof points.
Some of these are targeted for AI search. But many aren’t. Most are done for the sake of building the brand. AI search visibility is, in this framing, a byproduct of genuine brand construction. The probability of inclusion rises as the brand becomes more real, more coherent, and more present across the information ecosystem that models ingest.
This is also where the urn model becomes strategically instructive beyond metaphor.
In a Polya urn, the specific sequence of early draws shapes the long-run distribution. In AI search, the specific sources that cite you early (during a model’s training data window, or in the high-authority publications that RAG systems preferentially retrieve) have disproportionate influence on your long-run visibility. Not all marbles are equal.
A citation in a source that the retrieval layer trusts is worth more than a hundred mentions in sources it doesn’t. Scaling thousands of pages, in other words, doesn’t solve fundamental problems of authority or relevance. The engineering is in knowing which marbles to add and where.
Robustness Over Optimization
Nassim Taleb’s distinction between fragile, robust, and antifragile systems is helpful here. A fragile AI search strategy breaks when conditions change. A robust one survives. An antifragile one actually benefits from the volatility.
Imagine, for a moment, that self promotional listicles (and listicle swaps for off page brand mentions) don’t work forever. Imagine they are either table stakes due to Red Queen effects and automation, or simply not considered as authoritative by the models.
If that were to happen, would your position be fragile, robust, or antifragile?
The Distribution, Not the Draw
The funnel was a useful fiction for a more deterministic era.
AI search demands a different model, one that treats visibility as a probability distribution rather than a position, measurement as sampling and signal, and strategy as shaping a distribution of influence rather than holding a rank.
You can’t always control which marble gets drawn, just like you can’t control the conversation at every cocktail party around the world. But you can influence the composition of the urn. You can add marbles in the right places at the right time. You can build the kind of brand presence that makes favorable draws more likely across more contexts.
Want more insights like this? Subscribe to Field Notes


