
If you’re using a platform for AI visibility tracking, how are you choosing which prompts to import?
Are you:
- Tracking prompts across multiple customer journey stages?
- Choosing prompts based on competitive analysis?
- Using keyword data for prompt sets?
You might be a marketer trying to come up with a set of prompts for a client, or an owner trying to understand your brand’s visibility. No matter the use case, the results you get from LLM prompt tracking are only as valuable as the prompts you choose as inputs.
I track prompts for research purposes, to analyze AI search trends and answer questions like: “Do LLMs recommend brands even when users aren’t shopping?” or “Where do LLMs source information about your brand?”.
My goal wasn’t to simulate a single brand’s customers. It was to measure how LLMs represent brands within a defined competitive ecosystem. For research, prompts must be externally valid and representative of a market category, not tailored to one company.
If I were building this for a specific brand, I would incorporate customer interviews, sales transcripts, and data on how people search on the brand’s site (at Omniscient, this is a service we offer clients).
If you want real signal, you need a structured set of prompts grounded in what people are actually searching for.
Here’s how I built mine.
Step 1: Define awareness first, not keywords
I developed a user journey framework adapted from the five-stage awareness model by Eugene Schwartz.
- Problem Unaware: Learning and seeking general information on a topic
- Problem Aware: Exploring ways to achieve an outcome by process framing, but not yet evaluating specific solutions
- Solution Aware: Actively evaluating vendors and making a purchase decision
These mirror top-of-funnel, middle-of-funnel, and bottom-of-funnel stages, but with a lens tailored to how users prompt LLMs.
For this prompt set, I chose an equal number of queries across all three stages.
Note: If you’re tracking your brand’s visibility (rather than conducting industry research), you may want an unequal distribution: lighter at earlier stages and heavier near purchase decisions.
Step 2: Build intent buckets within each stage
Within journey stages, there are varying intentions. I wanted to ensure an equal distribution of user intents represented in my dataset, so I defined sub-buckets as my next step.
1. Problem Unaware
- Informational
- What is [concept]?
- Why does [method] matter?
- What causes [event]?
- What’s the difference between [concept] and [concept]?
2. Problem Aware
- Jobs-to-Be-Done
- How do I increase [metric]?
- How do I automate [process]?
- What’s the best way to [process]?
- What is the best approach to [process]?
- How-To / Workflows
- How to implement [strategy]?
- Create an SOP for [process]
- Common mistakes in [strategy]
- Template for [process]
3. Solution Aware
- Direct Brand Evaluation
- Is [brand] worth it?
- Is [brand] good at [process]?
- Category Exploration
- Best tools for [strategy]
- Top software for [process]
- Comparison
- [Brand X] vs [Brand Y]
- [Brand] alternatives
- Proof / Evidence
- [Brand] reviews
- What do customers say about [brand]?
- Implementation / Functionality
- How do I implement [product]?
- Does [brand] integrate with [existing stack]?
- Pricing
- How much does [product] cost?
- [Brand] cost breakdown
This prevented the dataset from skewing too heavily toward informational or comparison-style prompts and ensured balanced intent representation across stages.
Step 3: Define topics
For this research, I narrowed the scope to the B2B organic growth ecosystem. I focused on the topics where brands compete for attention in search-driven growth.
These are the 10 sub-topics I chose:
- SEO
- Technical SEO
- Programmatic SEO
- GEO
- AI Search Optimization
- Content Marketing
- Link Building
- Digital PR
- Digital Analytics
- Marketing Attribution
Then, within each intent bucket, I assigned an equal number of queries per topic.
For your business, topics could be products, services, features, or use cases – whatever reflects how your buyers think. For client work, we would expand or narrow topics based on the company’s actual ICP and product surface area.
Step 4: Choose prompts based on what users are actively searching for
I didn’t want to invent what I thought users might ask. I wanted prompts grounded in real search demand, translated into LLM-friendly phrasing without losing their original intent.
The sourcing tactics here were influenced by Ahrefs’ work on custom prompt tracking. I used similar methods, but as inputs into the structured framework defined in the earlier steps.
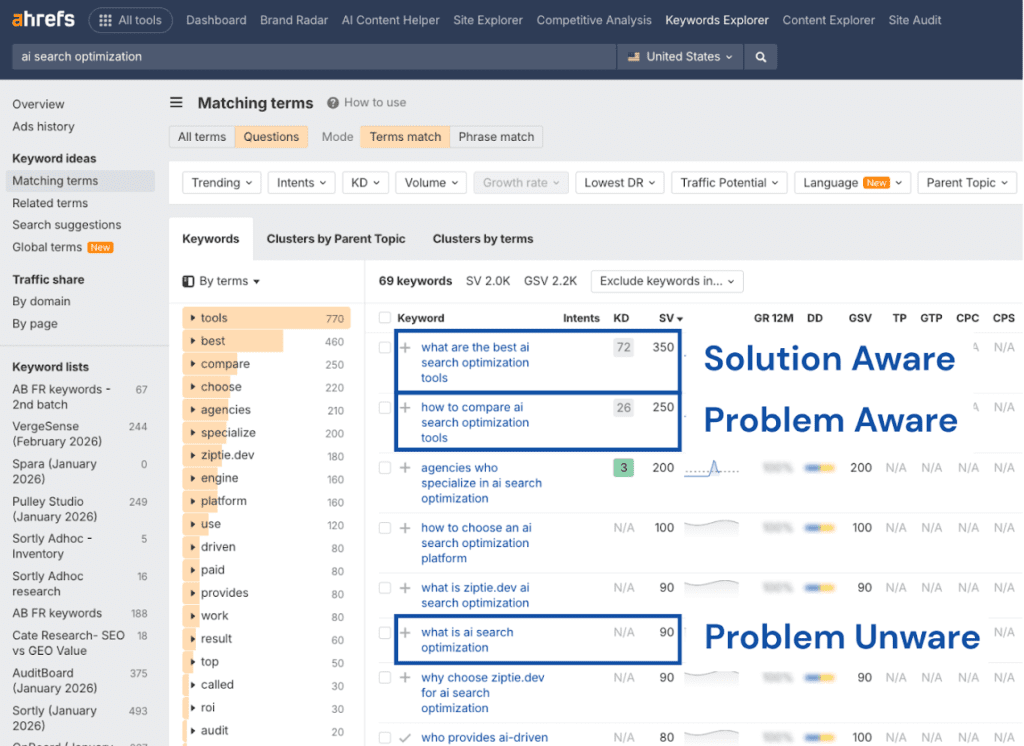
1. Start with high-volume question keywords
Using Ahrefs Keywords Explorer under the ‘Questions’ tab, I identified the most searched queries for each topic and mapped them to the appropriate journey stage.
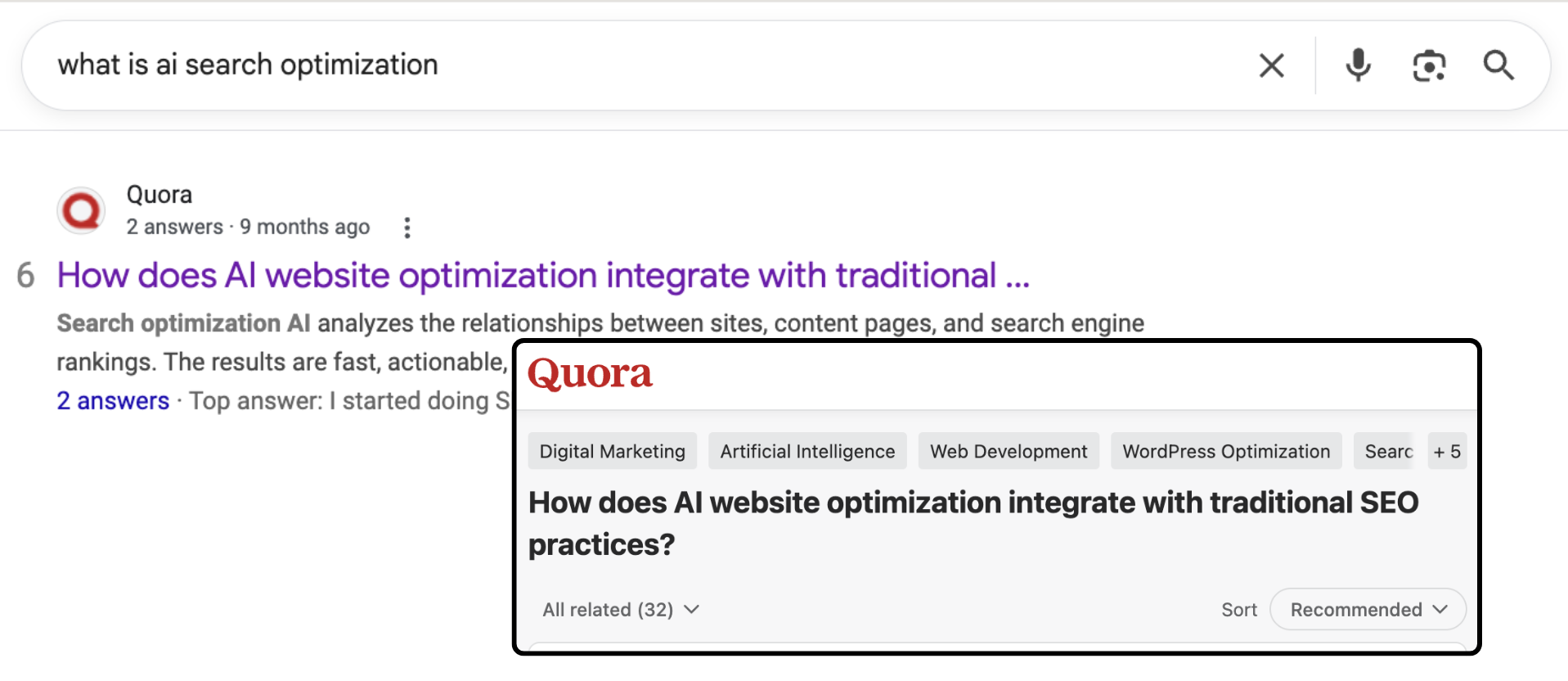
2. Expand with real-world phrasing
I validated and enriched those queries using forums and Google’s “People Also Ask,” which surfaced more nuanced, conversational variations.
For example, a forum question like:
“What’s an example of a decent content strategy? My background is in journalism and I recently switched to a content marketing type role. The importance of a content strategy is discussed a lot online but it’s hard to see what a content strategy looks like. I know it’ll look different according to the industry and audience but would be great to see a rough example.”
– Reddit User
adds context and specificity that pure keyword data often misses.
3. Add LLM-native variations
With their ‘Follow-ups’ feature, Perplexity took my basic Ahrefs root question and gave me unique variations to add diversity to my prompt set.

4. Use AI to fill the gaps (last resort)
I only used AI-generated prompts when I couldn’t find enough real-world queries, particularly for branded searches with limited keyword data.

I gave Perplexity a well thought-out prompt, and I was happy with the output suggestions.
Using these four strategies, I built a balanced mix of:
- Short vs. long prompts
- High vs. low explanatory detail
- Forum-style specificity
- LLM-native phrasing
Step 5: Control qualifier density
By “contextual qualifiers,” I mean the additional constraints or descriptors a user includes beyond the core question.
I wanted diversity between:
- “Best SEO tools” and
- “Best SEO tools for a 10-person SaaS startup with a limited budget using HubSpot”
I hypothesized that qualifier density tends to increase as users move closer to a purchasing decision. Early-stage queries often seek broad understanding, while later-stage queries typically reflect constraints, budget considerations, and integration requirements.
While this pattern isn’t universally true, modeling it this way allowed the dataset to reflect a plausible progression in buyer specificity.
My qualifiers:
- Persona: industry / role / business model
- Company size: solo project / SMB / mid-market / enterprise
- Constraints: budget / security / compliance / timeline / team skill
- Tool stack: must work with [tool] / that can be used with [product]
I distributed these qualifiers intentionally:
| Journey Stage | Qualifier Depth | Qualifier Focus |
| Problem Unaware | Minimal (<10%) | Persona |
| Problem Aware | Moderate (~30%) | Company Size |
| Solution Aware | Higher (~60%) | Constraints + Tool Stack |
LLM outputs shift significantly based on how much context is provided. A generic prompt produces broad category answers, while a highly qualified prompt dramatically narrows recommendations. If qualifier density isn’t controlled, prompt tracking results can skew toward either overly broad or overly constrained outputs.
Sample Prompts
Below are representative examples from the final dataset, illustrating how prompts vary by stage, intent, topic, and source strategy:
.table-3-1 { width: 100%; table-layout: fixed; border-collapse: collapse; font-family: “DM Sans”, sans-serif; font-size: 11px; } /* Base cell styling */ .table-3-1 th, .table-3-1 td { border: 1px solid #000; padding: 12px; vertical-align: top; overflow-wrap: anywhere; } /* Updated column widths */ .table-3-1 col:nth-child(1) { width: 40%; } .table-3-1 col:nth-child(2) { width: 15%; } .table-3-1 col:nth-child(3) { width: 17%; } /* Wider */ .table-3-1 col:nth-child(4) { width: 17%; } .table-3-1 col:nth-child(5) { width: 17%; } /* Header styling */ .table-3-1 thead th { text-align: center; font-weight: 700; font-size: 14px; /* Larger than body */ } /* Column 1 content LEFT aligned */ .table-3-1 tbody td:nth-child(1) { text-align: left; } /* Columns 2–5 content CENTERED */ .table-3-1 tbody td:nth-child(n+2) { text-align: center; }| Prompt | Funnel Stage | Intent Bucket | Topic | Source Strategy |
|---|---|---|---|---|
| Is SEO still worth focusing on in 2026? I’m asking because AI answers, zero-click searches, and constant Google updates seem to be changing how people find websites, and I want to know if SEO is still bringing real traffic and leads for others. | Problem Unaware | Informational | SEO | |
| What are examples of generative engine optimization? | Problem Unaware | Informational | GEO | Google PAA |
| How is AI changing digital marketing strategies in 2026? | Problem Unaware | Informational | Content Marketing | Quora |
| Common mistakes to avoid in programmatic SEO to keep up with compliance standards | Problem Aware | Jobs to be Done | Programmatic SEO | Perplexity Related |
| How to conduct a technical SEO website audit for a large-scale website with over 1,000,000 URLs? | Problem Aware | How To | Technical SEO | |
| How to measure link building ROI | Problem Aware | How To | Link Building | Perplexity Related |
| Which digital PR agency excels in SEO and PPC for enterprise B2B? | Solution Aware | Category Exploration | Digital PR | Ahrefs |
| Rankscale AI user reviews and results: showcase ratings, case studies boosting ChatGPT mentions, customer testimonials on competitor benchmarking, proven examples, and feedback from B2B agencies. | Solution Aware | Proof / Evidence | AI Search Optimization | Perplexity Generated |
| How do I properly set up HubSpot CRM for my small business? | Solution Aware | Implementation | Marketing Attribution | HubSpot Community |
The Final Dataset
The final dataset included 200 prompts, systematically balanced across:
- Awareness stage
- Intent type
- Topic
- Qualifier depth
Across ChatGPT, Perplexity, AI Overview, AI Mode, and Gemini, 200 prompts generated 3,000 unique outputs and 25,755 citations.
At that scale, patterns of brand presence and source citation behavior begin to stabilize. A smaller dataset would risk sampling bias. A larger one would introduce diminishing returns without proportionate analytical value.
Because each variable was intentionally controlled, the dataset avoids over-representing a single stage, intent type, or level of specificity.
Instead of just measuring “does a brand appear?”, it measures:
- Where it appears in the decision cycle
- Under which type of user intent
- With what level of contextual constraint
That structure turns prompt tracking from a loose collection of questions into a defensible measurement framework.
By solidifying this dataset, I am confident my research is representative of real queries within the B2B organic growth ecosystem. Using structured prompt tracking, I’ve been able to analyze patterns such as:


