
First, some humility.
There are a lot of people right now pretending they’ve figured it all out. They haven’t. (We haven’t either.) The smartest among us are operating from first principles, early patterns and research, small experiments, and agility — not dogma, not hacks.
The “playbook” (I really do bristle every time I use that word) is evolving in real time. LLMs are not only opaque, but they are constantly changing in interface, performance, features, and utility. Just a year ago, we saw a very different ChatGPT (with little search functionality and no Deep Research, for example).
So what worked last month may not work next month.
What we can do is work from what we know: how these models are trained, how they retrieve and synthesize information, and how brands show up inside that matrix.
Note: I’m running a 4 week cohort course with CXL on Organic Growth in the AI Era that will cover this stuff in depth. Check it out here.
The Architecture of Appearances
At a high level, most LLMs operate in one of two ways:
- Trained models with static datasets
- Retrieval-augmented generation (RAG) — i.e., models that browse the web or index fresh content
In the first scenario, you’re only visible if you were part of the training data.
That means brand mentions, earned media, Reddit threads, YouTube videos, your own website and content.
In the second, you can shape the output in near-real time. If you change a headline, publish a case study, or launch a new product page, you can start showing up or altering your mentions within hours.
Case in point, I whipped up a listicle on the “best GEO agencies” a few weeks ago, and within a day or so we were highly visible with merely one source and one mention on that source:

(Obviously, it’s not always that easy).
But in both cases, the rule is the same:
You must be worth mentioning.
This is where specificity, credibility, and surround sound SEO come in.
The Surround Sound Origin Story
Before we had language for GEO, we had Surround Sound SEO.
I built it while working on freemium acquisition at HubSpot. It started, as many good ideas do, with noticing a weird data point: a product listicle was converting at 10x above the blog average. HubSpot wasn’t even listed at the top. But it clearly worked.
So I wrote a few more myself. They converted too. I pulled the thread and started to unravel a pretty basic marketing fact: people comparison shop, stupid.
When someone searches “best CRM software,” they’re not looking for a single blog post. They’re looking for a shortlist of products to consider. They’re building a comparison table in their head (or a literal one to present to their boss).
If your brand shows up once, maybe you get a look. Twice, now you’re familiar. But if you show up on every page they visit, the question is no longer “who should I choose?” It’s “why wouldn’t I choose the brand that everyone else seems to choose?”
That’s the Surround Sound effect.
It is frequency meets discovery, equaling salience and affinity. It’s the old (oversimplified) advertising principle of “seven touches” applied to the modern search journey. But instead of hitting someone with the same display ad over and over, you appear in every trusted comparison they consult. Review sites. Listicles. Aggregators. Forums. Editorial mentions.
You become the obvious choice.
We built this playbook for HubSpot, and later at Omniscient, we’ve repeated it for several clients. And now, as the locus of discovery shifts to AI models, the same principles apply. But the game is harder. Because now, instead of persuading a searcher, you’re persuading a probabilistic language model with its own mechanism for identifying sources, citations, and how to summarize and deliver them.
Mentions Matter (Not Just Links)
Remember when backlinks were the coin of the realm?
They still matter. As you can clearly see after a few small experiments, ChatGPT Search, Perplexity, etc. have strong correlations with traditional search performance, as they are essentially leveraging classic indexation and rank and summarizing sources in the form of answers.
But increasingly, what matters more is mentions — especially on platforms that LLMs index heavily. Think Reddit, G2, TrustRadius, YouTube, and Wikipedia. Strategies such as effective Reddit marketing can turn authentic community mentions into durable visibility signals that LLMs readily absorb.
You don’t only need to rank #1 anymore. You need to show up everywhere the conversation happens.
The principles from Surround Sound SEO are still valid, though LLMs are widening the surface areas of attention. It’s not just the top 10, top 20, top 30 search results that show up in citations, or inform the training data. Ubiquity, omnipresence against your category and aligned with your messaging and positioning, is the name of the game.
The cool part is you can already see which sources and surface areas matter for your brand inclusions.
Peec.ai, and a ton of other similar tools (Profound, Otterly, and then Semrush and Ahrefs are getting in the game, too), show you not only your probability of visibility against a prompt, but they show you which sources are cited, drilling down to individual pages.
This is Convert’s visibility against a “VWO alternatives” prompt:
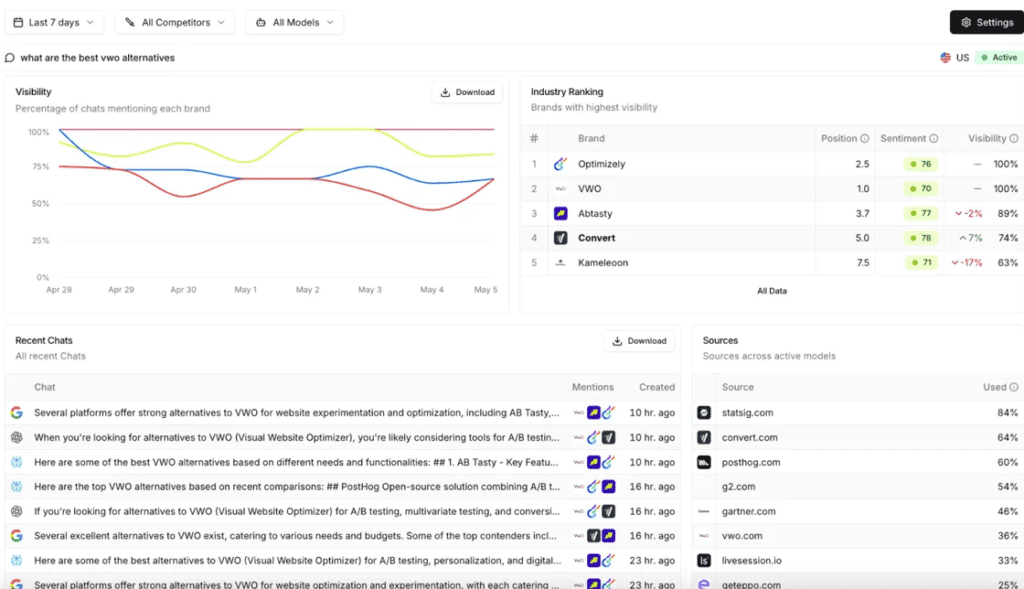
You can see on the right-hand side the probability of a domain being in the citations. Click into one, and you can see the page-level citations:
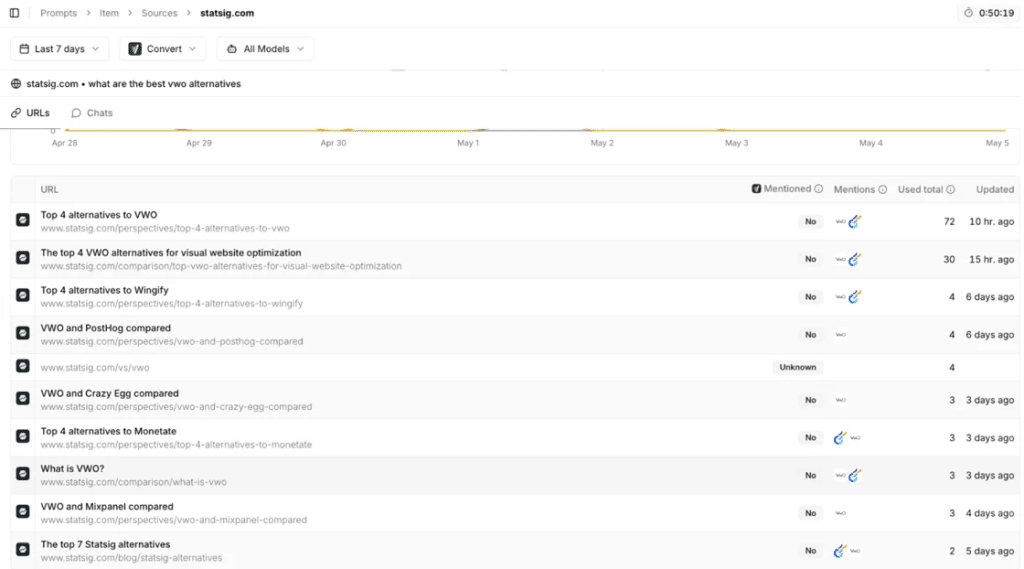
So, the goal? Get included where you’re not (or usurp them as sources, presenting a somewhat more complex tactical route, but one we’ve effectively executed many times).
Specificity and the Revenge of the Long Tail
People don’t ask LLMs general questions anymore. They ask:
“What’s the best project management tool for a 12-person remote design agency that needs Notion integration and hates Gantt charts?”
That’s not a keyword. That’s a story, a high resolution image of an individual person with a highly specific context.
And if your content doesn’t map to specific people and their specific questions, pain points, voice of customer phrases – with specific answers, highly credible in their execution, and useful in their orientation – it’s going to be tough to show up.
Fair enough, this was the trend with classic SEO, too. See: Ranch Style SEO. The Skyscraper Technique started crumbling years ago.
So the question becomes: are you answering questions your ICP is actually asking?
Most brands aren’t. They’re optimizing for volume. They’re still writing “Ultimate Guides.” They’re playing the 2017 game with 2025 rules.
Instead, try this:
- Identify real, high-context questions your ICP types into ChatGPT (or asks their peers).
- Map those to pages with expert quotes, proprietary data, or unique POVs and highly useful and specific information.
- Use language your customers would use (not marketers, not Surfer reports).
In other words, write like someone who knows the answer, not someone who’s read other blog posts about it.
Strategic Planning in a Post-Keyword World
This brings us to the question – probably the most interesting open ended question for well-trained SEOs trying to navigate the artificial intelligence paradigm:
How do you build a content roadmap when keywords are no longer the axis of discovery?
Historically, content strategy began with keyword research. You’d find terms with decent volume and low difficulty, match them to your ICP and funnel stage, and publish. Rinse and repeat.
But LLM queries don’t look like that.
They look like: “I’m building a mobile app for restaurant delivery in Chicago. I need an SEO agency that knows local markets, doesn’t do content, and is cool with short sprints. Who should I talk to?”
We don’t, to date, have any data on what people are searching or how many people are searching for any given prompt in LLMs (…yet).
So how do we plan, prioritize, and forecast impact?
The answer, to date, is probable to deal with uncertainty by applying what we do know about topics and their estimated reach, and then applying questions, conversational queries, prompt chains against those in execution.
Basically, you can still use keyword data to stack rank, at a high level, the relative popularity of a given topic. Say, “best SEO agencies” getting more searches than “best technical SEO agencies.” So a keyword and its associated data is still interesting, but must be intertwined with qualitative research.
In effect, the new roadmap building starts with customer research.
Voice-of-customer data. Jobs to be done. Pain points. Products, comparisons, and customer journey insights.
(I do hope you’ve come to the conclusion that, at the root level, what works for LLMs is pretty fundamental and resembles what some of us call “good marketing.”)
The cool thing about AI, too, is that you can use it to augment, uncover, and cluster common phrases that you’ve identified through your customer research, and instead of doing “keyword clustering,” you can do a more holistic version of it that includes 1st party research and customer understanding.
Same, same. But different.
Credibility Has a Shape
You’re going to see a lot of hacks come up.
One brand we know tried to hack the system.
They prompt-engineered their name into dozens of LLM answers. It worked. For three weeks. Then OpenAI updated the model, the mentions disappeared. Fleeting, ephemeral, short term thinking.
There’s another hack today. You can manipulate LLMs’ reinforcement learning by giving them “feedback” to alter their outputs. How long do you think this is going to be effective?
LLMS.txt, reinforcement learning hacking. You can even hack your credibility, you know?
There’s always going to be a hack, a short term arbitrage.
But know that these things get ironed out and regress to the mean over time.
Wouldn’t you rather build your health on the basis of foundational truths like exercise and healthy eating instead of novel drugs and low certainty hacks?
Wouldn’t you rather set your brand up for long term, accumulating value than to waste time, effort, and energy on short term hacks?
LLMs may hallucinate, but they are surprisingly good at ignoring contrivance, especially over the long run and in aggregate. The more these systems mature, the more they reward hard-to-fake signals.
That means:
- Citable sources
- Expert-backed content
- Consistent brand mentions from independent media
- Real stories, real data, real insight
As Stefan Maritz from CXL put it:
“LLMs are trained on everything people are saying publicly. They pick up what’s real and ignore what’s contrived. If you’re genuinely being cited, quoted, linked to – your brand shows up.
This is how CXL consistently appears in LLM outputs for growth, conversion, and B2B marketing courses. We dominated the data the LLMs got trained on in the first place.
We didn’t hack anything. We are not even the biggest online education platform out there. People just kept mentioning us because we’ve been putting out valuable content for years.
When someone asks about CRO, growth or B2B marketing our name comes up because the training data is filled with people recommending us and telling other people on the internet why we are better than Udemy and worth the investment.
If people don’t recommend you, no model will either.”
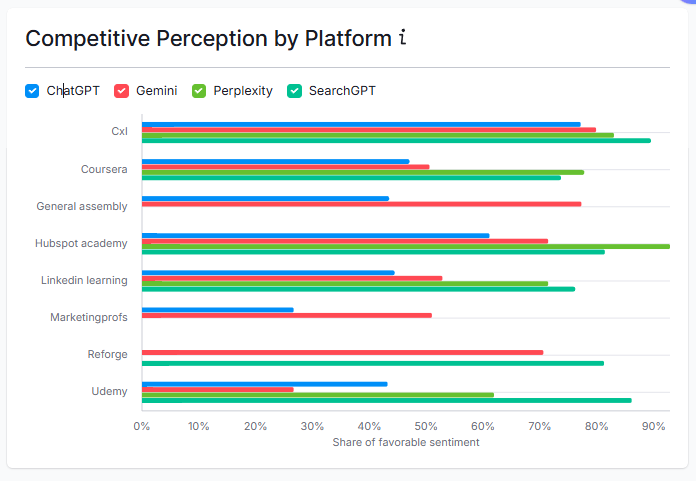
This is fun. To me it says that just doing the right thing (brand building, great content, navigable and accessible websites, etc.), instead of trying to fake it, may actually be easier and more effective over time.
What We Know (So Far) About On-Page SEO
There’s emerging research on GEO, including a 2024 study on what types of content most influence LLM outputs.
The TL;DR? Expert quotes, proprietary data, high semantic similarity to the query, and fluency in writing style increase visibility in model answers. Prompt stuffing, keyword repetition, and generic phrasing do not.
What does this sound like to you?
Oh yeah, great and highly credible content.
Onward.
A New Kind of Attribution
Of course, all of this raises the perennial question in marketing: how do you measure it?
The current truth is you won’t be able to measure it perfectly (not that you can measure anything in marketing perfectly). What we’re advising now is to build a three-layer visibility model, mapping incremental revenue and pipeline from AI, identifying referral traffic and pages, and then auditing visibility against key prompts and phrases:
- Self-reported attribution. Where did you hear about us? We’re getting a ton of color from simply asking this on our forms, and then following up in sales calls. We’ve got clients who are seeing the same. You can also run incremental revenue and pipeline attribution, though with higher degrees of complexity.
- Track referral traffic from AI engines. It’s still clunky and obviously will not track the entirety of your visibility and influence, but tools like GA4 and Looker Studio make it easy, at the very least, to stack rank platform impact and pages that are appearing.
- Track visibility in LLMs against key prompts. Tools like Peec.ai are actually really cool, and easy to set up.
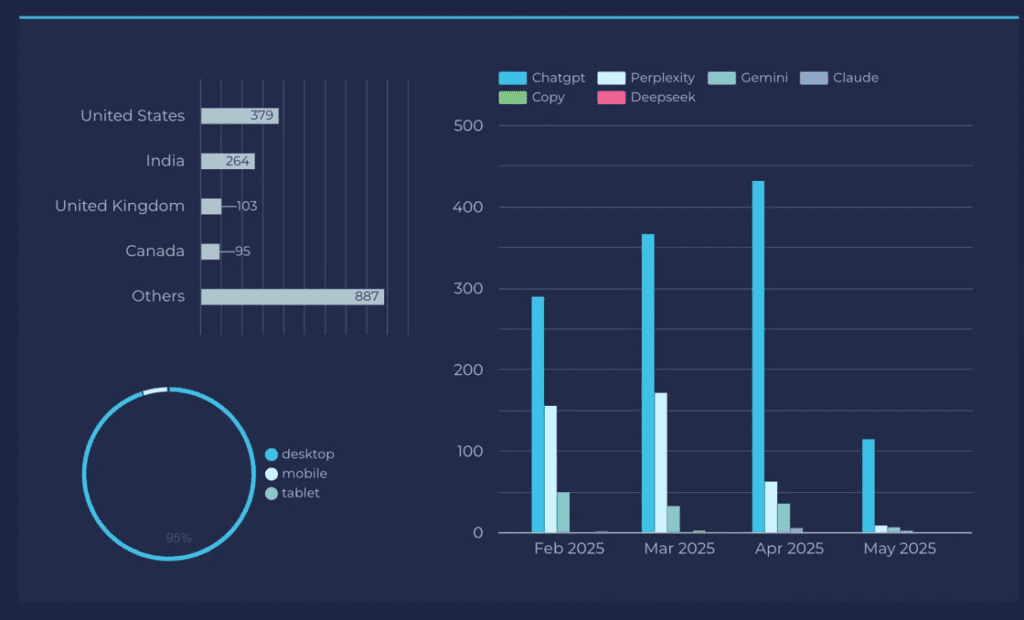
And maybe most importantly: measure what happens downstream. When someone lands on your site from a generative engine, how do they behave?
For us, LLM visitors convert at nearly 3x the rate of traditional organic search. They’re coming in with much higher intent, and they’re already highly informed about what we do and what they need.
It’s not word of mouth, per se. But it’s close, actually.
What’s actually happening to traffic? Is AI killing SEO?
There’s a ton of data, patterns, and takes floating around. Traffic down, revenue up? Maybe. Not always.
I’d say that the majority of our client portfolio – ambitious B2B scale-ups and enterprises – is flat, marginally down, or marginally up on the traffic front, with increasing leads and revenue.
That is not always the case, though. I’ve seen several publishers and consumer startups get crushed by AI overviews. Many seem to be experiencing a “great decoupling,” where impressions are growing but clicks are falling.
So it’s heterogenous and variables like industry, content portfolio, product, etc. play into how AI is affecting you. Mostly, AI overviews seem to be driving additional impressions but tanking clicks and traffic.
Anecdotally, ChatGPT, Perplexity, and Claude seem to be augmenting traditional customer journeys, increasing the pie, and even bringing in higher intent leads.
Courage, Experimentation, and a Little Humility
As humans, we crave certainty and will often detect patterns and causality where there is none. We don’t want to feel like we have no control over our outcomes. We want to feel some sense of agency.
So we grasp for things like reinforcement learning hacking, prompt hacking, LLMs.txt.
These are unlikely to save you, particularly over the long term.
What will do wonders, however, is a bit of courage in the face of uncertainty. A reliance on first principles, and asymmetric bets that may have upside in the GEO paradigm, but will also help you if nothing changes whatsoever (think: accessible websites, great navigation, customer journey comprehension, credible content, original data, and favorable brand mention). And a little bit of experimentation.
This stuff can sound daunting, but I want to reinforce the idea that we’re all learning together, and you’re probably not too far behind the curve.
Every tectonic shift in marketing creates opportunity. Those who see it early can build leverage that compounds. Those who wait for certainty will be left optimizing yesterday’s paradigm.
And if you’re still wondering where to start, I’ll leave you with this: build content that’s useful, cited, and credible. Get your brand mentioned in as many relevant places as possible. Track where you appear. Improve the gaps. Test hypotheses. Build a system.
Want more insights like this? Subscribe to our Field Notes.


